Title I-II OMB Survey Package Part B.12-13-21 to IES
Title I-II OMB Survey Package Part B.12-13-21 to IES.docx
Implementation of Title I/II-A Program Initiatives
OMB: 1850-0967


Implementation of Title I/II-A Program Initiatives — Survey Data Collection
Supporting Statement for Paperwork Reduction Act Submission
PART B: Collection of Information Employing Statistical Methods
December 2021
Contract ED-IES-11-C-0063
Submitted to:
Institute of Education Sciences
U.S. Department of Education
Submitted by:
Westat
An Employee-Owned Research Corporation®
1600 Research Boulevard
Rockville, Maryland 20850-3129
(301) 251-1500
and
Mathematica
P.O.
Box 2393
Princeton, NJ 08543-2393
Contents
Page
Part B. Collection of Information Employing Statistical Methods 1
B.1. Respondent Universe and Sample Design 1
B.1.1. State Sample 1
B.1.2. School District Sample 1
B.1.3. School Sample 2
B.2. Information Collection Procedures 3
B.2.1. Data Collection 3
B.2.1.1 State Survey 3
B.2.1.2 District Survey 3
B.2.1.3 Principal Survey 4
B.2.2. Statistical Methodology for Stratification and Sample Selection 4
B.2.2.1. States 4
B.2.2.2. Nationally representative sample of school districts 5
B.2.2.3. Nationally representative sample of schools 9
B.2.3 Estimation Procedures 12
B.2.4. Degree of Accuracy Needed 12
B.2.5. Unusual Problems Requiring Specialized Sampling Procedures 16
B.2.6. Use of Periodic (less than annual) Data Collection to Reduce Burden 16
B.3. Methods for Maximizing the Response Rate 16
B.4. Test of Procedures 17
B.5. Individuals Consulted on Statistical Aspects of Design 17
Appendix A.State survey A-1
Appendix B.District survey B-1
Appendix C. Principal survey C-1
Appendix D. Notification and reminder materials D-1
Tables
B-1. Distribution of districts by poverty strata 5
B-2. Distribution of districts by primary poverty strata and district-size strata 6
B-3. Distributions of schools by CSI status and district poverty stratum after expected nonresponse attrition 10
B-4. Distribution of district frame and sample districts by number of CSI schools 11
B-5. Distributions of districts by
poverty stratum and precision of
national
district-level estimates 13
B-6. Comparison of district poverty-level strata power 13
B-7. Distributions of schools by CSI status and district poverty stratum and precision of national school-level estimates 14
B-8. Power calculation for comparing CSI and non-CSI schools 15
Part B. Collection of Information Employing Statistical Methods
When the primary federal law governing K–12 schooling was updated in 2015 as the Every Student Succeeds Act (ESSA), it shifted many decisions to states and districts. However, through two of its core programs (Title I and Title II-A), ESSA retained federal requirements for states to set challenging content standards, assess student performance, identify and support low-performing schools, and promote the development of the educator workforce. How states and districts respond to the combination of flexibility and requirements and how policies are enacted in schools and classrooms will determine whether ESSA stimulates educational improvement as intended, which is particularly important in the wake of educational disruptions wrought by the coronavirus pandemic. The U.S. Department of Education (the Department), through its Institute of Education Sciences (IES), is requesting clearance for data collection activities to support an implementation study of Title I and Title II-A. This package requests clearance for the state, district, and principal survey instruments and to administer these surveys.
B.1. Respondent Universe and Sample Design
The study sample will include the universe of states, the District of Columbia and Puerto Rico, and nationally representative samples of districts and schools. The school sample will be nested in the district sample.
B.1.1. State Sample
We will survey all 50 states, the District of Columbia, and Puerto Rico.
B.1.2. School District Sample
A nationally representative sample of districts will be selected. This will provide unbiased estimates of district characteristics and serve as the first stage of selection for the school sample.
The study also is interested in statistically comparing the implementation of initiatives promoted by Title I and Title II by district level of poverty, district urbanicity, and size of districts based on student enrollment. Poverty is of interest because Title I is specifically intended to ameliorate the effects of poverty on local funding constraints and education opportunity. District urbanicity (i.e., location in an urban, suburban, town, or rural area) is of interest because of the relationships between educational opportunity and rural isolation and the concentration of poverty in urban schools. District size is of interest because it may be related to district capacity to develop and implement programs.
In addition, the district sample design will incorporate whether districts have schools identified for Comprehensive Support and Improvement (CSI) under Title I of ESSA. A major component of the study focuses on CSI schools. Districts are encouraged by federal policy to focus on these lowest-performing schools to bring about improvements.
The study team received permission from the National Center for Education Statistics (NCES) to use the 2022 district frame for the National Assessment of Educational Progress (NAEP) as the starting district frame for this data collection. The 2022 NAEP frame is based on the provisional 2019–20 NCES Common Core of Data (CCD) district universe file updated with CCD school file information. The NAEP frame-building process filters out entities on the CCD that are not really districts. The study team processed this frame to subset out entities not of interest to the study (such as schools with only pre-kindergarten or kindergarten grades) and limited the frame to traditional public school districts and independent charter local education agencies with at least one eligible school and at least one enrolled student. The processed NAEP frame was supplemented with data from the U.S. Bureau of the Census’s district-level SAIPE (Small Area Income and Poverty Estimates) program for school-district percentages of children in families in poverty. The frame also included information obtained from EDFacts or state websites on whether the district included at least one CSI school.1
We will draw a district sample of 1,150 out of 17,125 school districts and charter local education agencies nationally. See Table B-2 in Section B.2 for the universe counts by stratification classifications. (See section B.2.2.2 for additional information on the design for the district sample.)
B.1.3. School Sample
A nationally representative sample of schools will be selected. The school sample will be a two-stage sample, nested within the sampled districts. This will provide unbiased estimates of school characteristics.
In addition to examining the implementation of initiatives in schools nationwide, we also will statistically compare policy implementation by CSI school status, Title I school status, and school grade span. As noted above, there is interest in examining the types of strategies and their implementation in CSI schools. School Title I status is of interest because the focus of Title I funds and requirements is to influence state and district policy to improve equitable access to educational opportunities. A school’s grade span is of interest because we anticipate that implementation of state content standards and aligned assessments, as well as accountability measures and approaches to improving student outcomes, may differ by grade level.
The study team received permission to use the 2022 NAEP school frame, which is based on a provisional 2019-20 CCD school universe file. We processed the frame to subset it to schools in the 50 states, District of Columbia, and Puerto Rico and excluded schools that were not of interest to the study such as schools with only pre-kindergarten or kindergarten grades. We supplemented the frame with the school’s CSI status.2
We will draw a sample of 1,725 schools nested within the sample of 1,150 districts. (The universe of schools is 92,386 schools.) The school sample will consist of 690 CSI schools and 1,035 non-CSI schools. As CSI schools are a small portion of the school frame (5,608 schools), this is a considerable oversampling of CSI schools. This will allow for high-precision comparisons of CSI and non-CSI schools, which is a priority subgroup comparison for the study. See Table B-3 in section B.2 for the universe counts by stratification classification. (See section B.2.2.3 for additional information on the design for the school sample.)
B.2. Information Collection Procedures
B.2.1. Data Collection
B.2.1.1 State Survey
In early March 2022, the study team will send the Chief State School Officer and the state Title I administrator a notification letter (see Appendix D) explaining the study, thanking the state for its previous participation in the study’s prior rounds of data collection, and emphasizing the importance of the state’s involvement in this data collection. States receiving Title I and Title II-A funds are expected to cooperate in Department evaluations of these programs (Education Department General Administrative Regulations (EDGAR) (34 C.F.R. § 76.591)). The state letter will note the expected nature of the state’s response. We will send the notification letters via email and postal mail to increase the likelihood that addressees will receive our communications in a timely manner.
About one week later, the study team will email the Title I Director the survey invitation letter. This letter will include information to access the web survey and will refer to the notification letter. The state surveys may require input from several key individuals. The Title I Director will serve as the primary contact for the survey (unless the Chief State School Officer or Title I Director offers a designee) and will coordinate input from the multiple respondents as needed. The state survey URL will include embedded login information to: (1) reduce the number of communications from the study team to the state to securely provide login information separate from the survey URL; and (2) reduce the burden of sharing access to the survey within the state if a different respondent is identified as the best person to complete the survey.
Project staff will monitor completion rates, review the instruments for completeness throughout the field period, and follow up by email and telephone as needed to answer questions and encourage completion. (See Appendix D for follow-up emails.) During these calls, respondents will be given the option of completing the survey by telephone with the researcher.
B.2.1.2 District Survey
The district sample consists of traditional public school districts and independent charters (i.e., not part of a traditional public school district). The vast majority of these independent charters operate only one school, but a few operate more than one school. Most, but not all, of the traditional public school districts and charters have one or more schools sampled for the study. The study team has tailored the collection approach and materials to fit this variety of situations, as described below.
Since the school survey (see Section B.2.1.3) will launch prior to the district survey, the study team will send a notification letter to superintendents so they are aware of the upcoming study activities in their district (See Appendix D). This letter will be sent in February 2022, a week before the school survey launches, to the following: traditional public school districts with sampled schools, and charters that operate two or more schools and have schools sampled for the study. For charters that operate only one school, and that school was sampled for the study, the study team will send the charter a letter requesting that they complete both the district and school surveys. This letter will be sent at the time of the school survey launch and will indicate that the invitation for the district survey will be sent in March.
In March 2022, the study team will send a district survey invitation letter (see Appendix D) by email and postal mail to the superintendents of the sampled districts. The invitation letter will introduce the district survey, and underscore the importance and benefits of district participation in the survey. Sending the invitation letters both by email and postal mail will increase the likelihood that addressees will receive our communications in a timely manner. Like the state letter, the district letter will note that districts receiving Title I and Title II-A funds are expected to cooperate in Department evaluations of those programs, per the EDGAR regulations.
The district survey may require input from several key individuals. The district superintendent will serve as the primary contact for the survey (unless the superintendent offers a designee) and will coordinate input from the multiple respondents as needed. We will follow all required procedures, and as necessary, obtain approval of the district for its participation in the study through submissions of the required research application.
The invitation letters will include the district survey URL along with the username and password, which will be personalized for each district. All communications will include study contact information (i.e., toll-free study number and a study email address) for respondents’ questions and technical support. Trained research staff will be assigned to answer the study hotline and reply to emails in the study mailbox. Staff will be trained on the purpose of the study, the expectation for district respondents to participate in the evaluation, and the details for completing the web-based survey. Content questions will be referred to the study leadership. An internal FAQ document will be developed and updated as needed throughout the course of data collection to ensure that all research staff have the most current information on the study. The study team will send reminder emails to districts about three weeks after the invitation letter (see Appendix D).
B.2.1.3 Principal Survey
In February 2022, a week after the district notification letters have been sent, the study team will send a survey invitation letter (see Appendix D) by email and postal mail to the principals of the sampled schools. The invitation letter will introduce the survey and underscore the importance of participation in the survey. Sending the invitation letters both by email and postal mail will increase the likelihood that addressees will receive our communications in a timely manner. Principals will be told that their participation in the survey is voluntary.
The invitation letters will include the principal survey URL along with the username and password, which will be personalized for each school. All communications will include study contact information (i.e., toll-free study number and a study email address) for respondents’ questions and technical support. Staff trained on the study, online survey system, and voluntary nature of the survey will answer the study hotline and reply to emails in the study mailbox. Like the process for the district survey, content questions will be referred to the study leadership and an internal FAQ document will be developed and updated for staff. The study team will send reminder emails to principals about three weeks after the invitation letter (see Appendix D).
B.2.2. Statistical Methodology for Stratification and Sample Selection
B.2.2.1. States
The study will include all 50 states, the District of Columbia, and Puerto Rico. Based on experience with the study’s prior data collections in 2014 and 2018, the study design assumes that all states will respond.
B.2.2.2. Nationally representative sample of school districts
The team will select the district sample using a stratified simple random sample approach. The district sample will be stratified by poverty status and district size.3 The poverty strata are defined based on the percent of families with children in poverty. The high-poverty stratum consists of districts with percentages greater than the national 75th percentile. The low-poverty stratum consists of districts with percentages less than the national 25th percentile. The medium-poverty stratum is all other districts4. Table B-1 presents the distribution of frame districts by poverty strata.5
Table B-1. Distribution of districts by poverty strata
Poverty Stratum |
Definition |
Number of districts |
Percent of frame districts |
Aggregate enrollment (in 1000s) |
Percent aggregate enrollment |
High |
Child poverty greater than 20.73% |
4,832 |
28.2% |
12,254 |
24.5% |
Medium |
Child poverty 8.57% up to 20.73% or missing |
8,705 |
50.8% |
25,289 |
50.6% |
Low |
Child poverty less than or equal to 8.57% |
3,588 |
21.0% |
12,425 |
24.9% |
Total |
|
17,125 |
100.0% |
49,968 |
100.0% |
A total of 1,150 districts will be sampled, with oversampling of high-poverty districts by a factor of 2.73 as compared to medium-poverty districts in order to strengthen precision for high-poverty districts, and also facilitate the oversampling of CSI schools, which concentrate heavily within high-poverty districts. Our goal is a sample size of 550 for high-poverty districts, 400 for medium-poverty districts, and 200 for low-poverty districts.6 Based on the near 100 percent response rates for the study’s 2014 and 2018 district surveys, we expect only limited nonresponse for the 2022 district survey, and, as a result, do not plan to increase the sample size for nonresponse attrition.
Table B-2 presents a breakdown of district-size strata and the three poverty strata. The relative sampling rate within the poverty strata is determined for each district size stratum by the square root of mean enrollment.7 The primary parameter then is the assigned sample sizes to the three district poverty strata.
Table B-2. Distribution of districts by primary poverty strata and district-size strata
Poverty Stratum |
District Size Strata |
Frame district count |
Frame enrll (in 1000s) |
Stratum mean enroll-ment |
Rela-tive sam-pling rate |
Total mea-sure of size |
Expect-ed sample size |
Sampling rate |
High |
E1--Enrll 1 to 500 |
2,054 |
502 |
245 |
1.00 |
2,050 |
104.0 |
5.06% |
High |
E2--Enrll 501 to 1,500 |
1,488 |
1,278 |
859 |
1.87 |
2,782 |
141.1 |
9.48% |
High |
E3--Enrll 1,501 to 5,000 |
875 |
2,338 |
2,672 |
3.30 |
2,886 |
146.4 |
16.73% |
High |
E4--Enrll 5,001 to 15,000 |
288 |
2,376 |
8,251 |
5.80 |
1,669 |
84.7 |
29.40% |
High |
E5--Enrll 15,001 to 50,000 |
108 |
2,874 |
26,611 |
10.41 |
1,124 |
57.0 |
52.79% |
High |
E6--Enrll 50,001 to 150,000 |
14 |
963 |
68,774 |
16.73 |
234 |
11.9 |
84.87% |
High |
E7-Enrl 150.001 to 500,000 |
4 |
988 |
247,033 |
31.71 |
127 |
4.0 |
100.00% |
High |
E8-Enrll 500,001 or greater |
1 |
934 |
934,434 |
61.68 |
62 |
1.0 |
100.00% |
High |
Total |
4,832 |
12,254 |
|
132.50 |
10,934 |
550.0 |
11.38% |
Med |
E1--Enrll 1 to 500 |
3,349 |
813 |
245 |
1.00 |
3,342 |
62.1 |
1.86% |
Med |
E2--Enrll 501 to 1,500 |
2,657 |
2,380 |
896 |
1.91 |
5,074 |
94.3 |
3.55% |
Med |
E3--Enrll 1,501 to 5,000 |
1,768 |
4,769 |
2,697 |
3.31 |
5,859 |
108.9 |
6.16% |
Med |
E4--Enrll 5,001 to 15,000 |
643 |
5,396 |
8,391 |
5.85 |
3,758 |
69.9 |
10.87% |
Med |
E5--Enrll 15,001 to 50,000 |
236 |
6,008 |
25,459 |
10.18 |
2,403 |
44.7 |
18.93% |
Med |
E6-Enrl 50,001 to 150,000 |
43 |
3,509 |
81,599 |
18.23 |
784 |
14.6 |
33.88% |
Med |
E7-Enrl 150.001 to 500,000 |
9 |
2,414 |
268,260 |
33.05 |
297 |
5.5 |
61.44% |
Med |
Total |
8,705 |
25,289 |
|
73.53 |
21,518 |
400.0 |
4.60% |
Low |
E1--Enrll 1 to 500 |
933 |
231 |
248 |
1.01 |
938 |
17.6 |
1.89% |
Low |
E2--Enrll 501 to 1,500 |
966 |
879 |
910 |
1.92 |
1,859 |
35.0 |
3.62% |
Low |
E3--Enrll 1,501 to 5,000 |
1,129 |
3,241 |
2,871 |
3.42 |
3,860 |
72.6 |
6.43% |
Low |
E4--Enrll 5,001 to 15,000 |
423 |
3,417 |
8,078 |
5.74 |
2,426 |
45.6 |
10.78% |
Low |
E5--Enrll 15,001 to 50,000 |
115 |
2,886 |
25,097 |
10.11 |
1,163 |
21.9 |
19.01% |
Low |
E6-Enrl 50,001 to 150,000 |
19 |
1,254 |
65,982 |
16.39 |
311 |
5.9 |
30.82% |
Low |
E7-Enrl 150.001 to 500,000 |
3 |
516 |
172,136 |
26.47 |
79 |
1.5 |
49.78% |
Low |
Total |
3,588 |
12,425 |
|
65.06 |
10,637 |
200.0 |
5.57% |
Total |
Total |
17,125 |
49,968 |
|
271.09 |
43,089 |
1,150 |
6.72% |
To achieve the assigned sample sizes of 550, 400, and 200 for high-, medium-, and low-poverty districts, the high-poverty districts are oversampled at a rate of 2.73 compared to medium-poverty districts, and low-poverty districts are oversampled at a rate of 1.02 compared to medium-poverty districts. These particular oversampling rates will be carried through to the school sample (schools in high-poverty districts are sampled at a rate 2.73 times those of medium-poverty districts, etc.).
Further Details of District Sampling. Within the three primary poverty strata, we will implicitly stratify districts to improve the representativeness of the sample. This implicit stratification determines the sort order for systematic sampling using the probabilities of selection.
The highest-level stratifier within each explicit stratum is district CSI school status (district does not have a CSI school or district has at least one CSI school).
Within districts with at least one CSI school (‘CSI districts’), the sort ordering is based on:
Number of CSI schools (1, 2, 3, 4, 5 to 7, 8 to 10, 11 to 13, 14 or above)8;
Urbanicity (four strata: urban, suburban, town, rural);
Census Region (four geographic strata Northeast, South, Central, West); and
Student enrollment.
Within districts with no CSI schools (‘non-CSI districts’), the sort ordering is based on:
District Size Strata;
Urbanicity (four strata: urban, suburban, town, rural);
Census Region (four geographic strata Northeast, South, Central, West); and,
Student enrollment.
Coordinating the Title I/II-A district sample with other IES study samples. IES has a number of related studies underway, looking at other aspects of ESSA. In addition to the Implementation of Title I/II-A Program Initiatives, IES is conducting:
The Study of District and School Uses of Federal Education Funds, which examines how funds are distributed and used from the CARES Act as well as five major federal education programs: Part A of Titles I, II, III, and IV of ESEA, and Title I, Part B of the Individuals with Disabilities Education Act (IDEA). Data collection activities will include collecting detailed fiscal data for a nationally representative sample of districts for the 2021-22 school year.9
The Implementation of Key Federal Education Policies in the Wake of the Coronavirus Pandemic, which examines the influence of the coronavirus pandemic on how states and districts implement key provisions of ESSA and use federal funds, including those provided specifically to help districts recover from the pandemic. Data collection activities included a nationally representative survey of school districts in spring 2021. 10
The National Implementation Study of Student Support and Academic Enrichment Grants (Title IV, Part A), which examines how this new grant program is being carried out across the country, particularly the ways in which it supports school systems as they seek to recover from the coronavirus pandemic during the 2021–2022 school year. Data collection activities will include a nationally representative survey of Title IV-A coordinators in school districts in spring 2022.11
The Study of Educational Policies, Supports and Practices for English Learners: Implementation of Title III and Social and Emotional Learning, which provides a national portrait of Title III under ESSA and the strategies states, districts, and schools use to meet the needs of English learners (ELs) more generally. A particular focus will be on approaches to support social and emotional learning, given the challenges of engaging and serving ELs during the coronavirus pandemic. Data collection activities will include nationally representative samples of districts and schools in Spring 2023.12
The Study of School Improvement Plans and Their Implementation, which examines implementation of ESSA's CSI provisions in order to understand how states, districts, and schools are responding to the new requirements. Data collection activities will include a nationally representative survey of CSI schools in spring 2022.
In order to maximize learning about the implementation of ESSA while minimizing burden on respondents, IES is coordinating the sampling strategy for these studies with the Title I/II-A district sample in the following ways:
Maximizing overlap with Implementation of Key Federal Education Policies in the Wake of the Coronavirus Pandemic study sample because the Title I/II-A study, in part, wants to build directly on what was revealed in the districts’ 2021 data. Similarly, the sample for the Study of District and School Uses of Federal Education Funds was designed to maximize overlap with districts from the Coronavirus Pandemic study sample and will thus also maximally overlap with the 2022 Title I/II-A district sample. This overlap will allow the Title I/II-A survey data to contribute more context for the Uses of Funds study when examined in conjunction with the detailed fiscal data. In addition, the Title I/II-A survey will include a few questions for the Uses of Funds study. Maximizing overlap will be done by starting with the unconditional probabilities of selection determined by the Title I/II-A district sample design, but then conditioning on whether or not the district was sampled into the 2021 Coronavirus Pandemic study district sample.13
Minimize overlap with the district samples for the Title III and Title IV-A studies because IES wants to limit burden since those are substantively different topics and would otherwise be in the field at the same time or one year later. This minimization will be done after the drawing of the Title I/II-A sample, and there is no alteration of the Title I/II-A design or sample from this sequential coordination (the Title III and Title IV-A study samples are drawn conditionally on Title I/II-A inclusion to minimize overlap, respecting the final designated probabilities for those designs).
Because of the complete overlap in timing and data collection, as well as the strong overlap in content, the CSI schools-related questions for the Study of School Improvement Plans and Their Implementation will be embedded with the Title I/II-A surveys. This will maximize efficiency by eliminating the need for the Study of School Improvement Plans to administer a separate survey.
B.2.2.3. Nationally representative sample of schools
We plan to draw a school sample of 1,725 schools from the 1,150 sampled districts. Based on the response rate for the study’s 2014 school survey, we expect a response rate of 87 percent, which should result in 1,500 completed schools. In addition to supporting national estimates, a key driver of the school design is to support comparisons of CSI schools and non-CSI schools. The goal is that CSI schools have a coefficient of variation no greater than 10 percent, and that for the comparison of CSI to non-CSI schools there is 80 percent power to detect a 10 percent difference between these subgroups, assuming null percentages of 50 percent for each of these subgroups.
At the school level, we assume that relative school sampling rates for the three district poverty strata will parallel the rates of the districts, precluding any need for differential subsampling rates for schools within the three district poverty strata.14 We also will stratify by CSI status (CSI school or non-CSI school) to achieve the necessary sample size of 690 CSI schools (a considerable oversampling). The six strata defined by district poverty strata and by CSI school status are the primary strata for the school-level design.
Table B-3 summarizes frame school counts and expected sample counts for this overall design. Note that the aggregate sampling rates for the three district poverty strata within CSI status are in the ratios 2.73, 1.0, 1.02, paralleling the sampling rates for districts in the district stratification. The relative sampling rates for CSI vs. non-CSI schools are 8.1 (equal across the three poverty strata), to boost the CSI school sample size to the necessary 690 prior to the expected survey nonresponse attrition of 13 percent, which was informed by the study’s previous school response rate for a 2014 survey.
Table B-3. Distributions of schools by CSI status and district poverty stratum after expected nonresponse attrition
CSI status |
District poverty stratum |
Total frame schools |
Expected sample schools |
Relative sampling rate |
Design effect |
non-CSI |
High |
22,685 |
441 |
1.94% |
0.981 |
non-CSI |
Medium |
44,206 |
315 |
0.71% |
0.993 |
non-CSI |
Low |
19,887 |
144 |
0.73% |
0.993 |
non-CSI |
Total |
86,778 |
900 |
1.04% |
1.199 |
CSI |
High |
2,759 |
435 |
15.78% |
0.842 |
CSI |
Medium |
2,558 |
148 |
5.78% |
0.942 |
CSI |
Low |
291 |
17 |
5.89% |
0.941 |
CSI |
Total |
5,608 |
600 |
10.70% |
1.166 |
Total |
Total |
92,386 |
1,500 |
1.62% |
1.788 |
Note that the design effects within strata are less than 1 due to the inclusion of finite population corrections. The design effects from stratification for CSI and non-CSI schools are 1.166 and 1.199 respectively. The overall design effect from the six-level stratification at the national level is 1.788. The much higher design effect here is due to the considerable oversampling of CSI schools relative to non-CSI schools. We also will incorporate design effects from clustering.15
Table B-4 presents the numbers of CSI schools per sampled district. When we draw CSI schools from the districts, we will restrict the sample size for large districts to eight schools. This is reflected approximately in Table B-4 by providing a ‘cutoff’ value. Based on the distribution of sampled schools per CSI district (districts with at least one CSI school), the Coefficient of Variation (CV) of the cluster sizes is 0.83, so that the adjusted cluster size= 3.36.16
Table B-4. Distribution of district frame and sample districts by number of CSI schools
Count of CSI schools in district |
Frame districts |
Pct frame districts |
Exptd sample districts |
Pct sample districts |
CSI schools per smpld district |
Cutoff CSI schools per smpled district |
Respon-ding CSI schools per smpled district |
0 |
15,010 |
85.91% |
849 |
73.83% |
0 |
0 |
0.00 |
1 |
1,701 |
9.74% |
138 |
12.01% |
1 |
1 |
0.71 |
2 |
351 |
2.01% |
48 |
4.19% |
2 |
2 |
1.42 |
3 |
155 |
0.89% |
29 |
2.55% |
3 |
3 |
2.13 |
4 |
60 |
0.34% |
13 |
1.16% |
4 |
4 |
2.84 |
5 to 7 |
84 |
0.48% |
22 |
1.95% |
5.91 |
5 |
3.55 |
8 to 10 |
45 |
0.26% |
16 |
1.35% |
8.73 |
6 |
4.27 |
11 to 13 |
16 |
0.09% |
7 |
0.61% |
11.51 |
7 |
4.98 |
14 or more |
50 |
0.29% |
27 |
2.34% |
32.02 |
8 |
5.69 |
Total |
17,472 |
100.00% |
1,149 |
100.00% |
1,605 |
850 |
600 |
Further Details of School Sampling. The school sample will be drawn from the list of schools on the school frame within the 1,150 sampled districts. We will carry out a ‘two-phase sample’, where we re-order the set of schools in the sampled districts, and then carry out implicit stratification by systematically sampling from the sorted list. Implicit stratification will improve the representativeness of different types of schools in the sample. The sort hierarchy will be based first on CSI/non-CSI status. The CSI schools are sampled at a much higher rate than the non-CSI schools (690 CSI schools from 300 sampled districts having some CSI schools).
For CSI schools, we will implicitly stratify by the following:
state group, where state group is defined based on the percentage of their schools which are CSI (less than 5%; 5% to 10%, greater than 10%). Note that most states are in the first category, and only a few in the last. We consider this variable for the implicit stratification so the design incorporates the variation in this state policy decision.
sampled district,
grade span (elementary, middle, high, other).
For non-CSI schools, we will implicitly stratify by:
sampled district, and within district by Title I/non-Title I status, and grade span, using a serpentine sort. Most districts will have zero, one, or two non-CSI schools sampled, given that we are sampling 1,050 non-CSI schools from 1,150 districts. Note that districts with CSI schools will have a CSI school sample, and they may or may not have a non-CSI school also sampled.
Coordination of school samples with other IES studies. The Title I/II-A school sample design also had the objective of being coordinated with the school samples of the IES Study of Title III Implementation (described in section B.2.2.2) Study and IES 2022 NAEP, which has a large data collection that year. IES is coordinating the school sample designs across these data collections to minimize burden on the schools as much as possible. We minimize overlap by conditioning Title I/II-A school selection on inclusion into at least one of the 2022 NAEP school samples, doing this in a way to assure that the Title I/II-A design is ‘respected’ (the designated Title I/II-A unconditional probabilities are maintained). We will also coordinate overlap with the Title III school sample by drawing the two school samples together, evaluating overlap between the two (as the coordination at the district level will reduce expected overlap), and proceed with a conditionally independent school samples, or further minimize overlap conditionally. Another coordination activity is embedding CSI school-related questions from the Study of School Improvement Plans and Their Implementation in the Title I/II-A school survey, thereby eliminating the need for a separate school data collection.
B.2.3 Estimation Procedures
statistics (e.g., means, frequencies, and percentages), and straightforward statistical tests (e.g., tests for differences of means and proportions) will typically be used to answer the study’s research questions.
The study will include all 50 states, the District of Columbia, and Puerto Rico. Based on experience with the study’s prior data collections in 2014 and 2018, the study design assumes that all states will respond. Therefore, the study team does not plan to construct weights to account for state-level nonresponse.
Because of the use of a statistical sample, survey data presented for districts and schools will be weighted to generalize findings to the population of school districts and schools.
B.2.4. Degree of Accuracy Needed
We require statistical precision at the district and school levels.
District level
Table B-5 below presents the expected precision for national unit-count based estimates from this design.17 The design effects presented for each poverty stratum are the design effects induced from having a square-root-enrollment allocation. The overall design effect is 1.706, which includes the design effect from the non-proportional allocation to poverty strata. We expect a coefficient of variation (CV) for national district-level estimates of 3.85 percent. For a characteristic with a national mean percentage of 50 percent, the standard error will be 1.93 percent, resulting in a 95 percent confidence interval of [46.2 percent, 53.8 percent]. Based on the 2014 and 2018 study data, this is an adequate degree of precision for a descriptive implementation study.
Table B-5. Distributions of districts by poverty stratum
and precision of
national district-level estimates
Poverty Stratum |
District frame size |
District frame percent |
Sample size |
Design effect |
Effective Sample Size |
Standard error (50% sample pct) |
Half-width 95% CI |
High |
4,832 |
28.22% |
550 |
1.363 |
403 |
2.49% |
4.88% |
Medium |
8,705 |
50.83% |
400 |
1.492 |
268 |
3.05% |
5.99% |
Low |
3,588 |
20.95% |
200 |
1.470 |
136 |
4.29% |
8.40% |
Total |
17,125 |
100% |
1,150 |
1.706 |
674 |
|
|
|
Standard Error 50% sample pct |
1.93% |
|
|
|||
|
Lower bound 95% CI 50% sample pct |
46.2% |
|
|
|||
|
Upper bound 95% CI 50% sample pct |
53.8% |
|
|
|||
|
Coefficient of Variation |
|
3.85% |
|
|
||
Table B-6 presents the Minimum Detectable Difference (MDD) for subgroup comparisons by district poverty level, key subgroup comparisons for the study.18 These arise from tests of the null hypothesis of no difference at a 95 percent confidence level (with both sample percentages at 50 percent). For the high-poverty vs. low-poverty comparison, there is 80 percent power to detect a difference of 13.8 percentage points (50 percent vs. 36.2 percent). For the high-poverty vs. medium-/low-poverty comparison there is 80 percent power to detect a difference of 9.9 percentage points (50 percent vs. 40.1 percent).
Table B-6. Comparison of district poverty-level strata power
Poverty Stratum |
Sample size |
Effective sample size |
Null Pop Pct |
Null Std err |
95% sig test CR bound |
Alt Pop Pct |
Alt Std Err |
Power |
High |
550 |
403 |
50% |
2.49% |
|
50% |
2.49% |
|
Low |
200 |
136 |
50% |
4.29% |
|
36.2% |
4.12% |
|
|
|
|
|
4.96% |
9.72% |
13.8% |
4.81% |
80.19% |
High |
550 |
403 |
50% |
2.49% |
|
50% |
2.49% |
|
Med/Low |
600 |
401 |
50% |
2.50% |
|
40.1% |
2.45% |
|
|
|
|
|
3.53% |
6.91% |
9.9% |
3.49% |
80.40% |
School level
Table B-7 below provides predicted precision for national-level school estimates. We expect a CV of 3.46 percent for national school-level estimates. For a characteristic with a national mean percentage of 50 percent, the standard error will be 1.73 percent, resulting in a 95 percent confidence interval of [46.6 percent, 53.4 percent].
Table B-7. Distributions of schools by CSI status and district poverty stratum and precision of national school-level estimates
CSI status |
District poverty stratum |
Total frame schools |
Expected sample schools |
Relative sampling rate |
Stratifi-cation design effect |
Within district cluster effect |
Effective sample size |
non-CSI |
High |
22,685 |
441 |
1.94% |
0.981 |
|
449 |
non-CSI |
Medium |
44,206 |
315 |
0.71% |
0.993 |
|
317 |
non-CSI |
Low |
19,887 |
144 |
0.73% |
0.993 |
|
145 |
non-CSI |
Total |
86,778 |
900 |
1.04% |
1.199 |
1.016 |
739 |
CSI |
High |
2,759 |
435 |
15.78% |
0.842 |
|
517 |
CSI |
Medium |
2,558 |
148 |
5.78% |
0.942 |
|
157 |
CSI |
Low |
291 |
17 |
5.89% |
0.941 |
|
18 |
CSI |
Total |
5,608 |
600 |
10.70% |
1.166 |
1.590 |
324 |
Total |
Total |
92,386 |
1,500 |
1.62% |
|
|
837 |
|
|
Total design effect |
|
|
|
1.792 |
|
|
|
Standard Error 50% sample pct |
|
|
1.73% |
||
|
|
Lower bound 95% CI 50% sample pct |
|
|
46.6% |
||
|
|
Upper bound 95% CI 50% sample pct |
|
|
53.4% |
||
|
|
Coefficient of Variation |
|
|
|
3.46% |
|
Table B-8 below presents power calculations for comparing CSI schools and non-CSI schools under this design, which is a key subgroup comparison at the school level.19 There is a stratification design effect arising from oversampling at the district level for poverty and district-size. There is also here a cluster design effect as schools cluster within sampled districts. We assume an intra-district correlation coefficient of 25 percent.20 The effective sample size is the nominal sample size divided by the product of the design effects. The standard error of sample percentages of 50 percent are computed for each of the two subgroups. The CV for CSI schools is computed as 5.6 percent. The standard error of the difference of the two subgroup percentages is computed under the null hypothesis of no difference. For the CSI school vs. non-CSI school comparison, there is 80 percent power to detect a difference of 9.33 percentage points.
Table B-8. Power calculation for comparing CSI and non-CSI schools
|
CSI schools |
Non CSI schools |
Comparison |
Intra-district correlation |
0.25 |
0.25 |
|
District sample |
303 |
847 |
|
School sample |
600 |
900 |
|
Mean cluster size |
1.979 |
1.063 |
|
Adjusted cluster size |
3.358 |
1.063 |
|
Cluster design effect |
1.590 |
1.016 |
|
Stratification design effect |
1.166 |
1.199 |
|
Effective school sample size |
323.8 |
739.3 |
|
Coefficient of Variation |
5.6% |
|
|
Std Error Null 50% Pct |
2.78% |
1.84% |
|
Std Error Diff |
|
|
3.33% |
MDD |
|
|
9.33% |
B.2.5. Unusual Problems Requiring Specialized Sampling Procedures
There are no unusual problems requiring specialized sampling procedures.
B.2.6. Use of Periodic (less than annual) Data Collection to Reduce Burden
The surveys will be conducted during the 2021–22 school year.
B.3. Methods for Maximizing the Response Rate
The study team achieved very high response rates of 95 percent or more for the state and district surveys during the study’s 2018 data collections (which did not include a principal survey). We expect to achieve similarly high response rates again for the 2022 state and district surveys. We plan to work with states and school districts to explain the importance of this data collection effort and to make it as easy as possible to comply. For all respondents, a clear description of the study design and the nature and importance of the study will be provided. State and district respondents will also be reminded that states and districts receiving Title I and Title II-A funds are expected to cooperate in Department evaluations of these programs (Education Department General Administrative Regulations (EDGAR) (34 C.F.R. § 76.591)).
Methods for the state survey. We will be courteous but persistent in follow-up with participants who do not respond in a timely manner to our attempts. We also will be very flexible gathering our data, allowing different people to respond to the different content areas and in whichever mode is easiest -- electronic, hard copy, or telephone format. Project staff will monitor completion rates, review the instruments for completeness throughout the field period, and follow up by email and telephone as needed to answer questions and encourage completion. During these calls, respondents will be given the option of completing the survey by telephone with the researcher.
Methods for the district and principal surveys. Obtaining high response rates for the principal survey will be particularly challenging, because schools are likely still to be struggling with the challenges of the global pandemic and its fallout. The study will use a number of data collection strategies to minimize nonresponse, thereby maximizing study response rates, for the principal survey. These strategies have contributed to obtaining high response rates for previous district surveys and will be used again for the 2022 district survey as well as the principal survey. These strategies are discussed below.
Using a data collection plan designed to minimize burden and maximize response. The study will send superintendents with sampled schools a notification letter by postal mail in February, before schools are contacted. This letter, on U.S. Department of Education letterhead and signed by the Title I/II-A Implementation Study federal project officer, informs superintendents about the data collection that will be taking place in their district (See Appendix D). Subsequent communications to principals will include the statement that their district has been informed about the study. A copy of the district notification letter can be provided to principals upon request.
Districts and schools will receive their survey invitation letters by postal mail. These invitation letters, on U.S. Department of Education letterhead and signed by the Title I/II-A Implementation Study federal project officer, will include information about accessing the surveys online. These invitation letters will help establish the legitimacy of the study. A short time after the postal mailing, the invitation letters will also be sent by email. Sending the invitation letters by both postal mail and email will increase the likelihood that addressees will receive our communications in a timely manner. Subsequently, reminder emails with information about accessing the surveys online will be sent to facilitate response. Study team staff will conduct telephone and individualized email follow-up for nonresponse. These individualized telephone and email contacts will continue throughout the data collection period, supplemented as needed by group email reminders.
Personalizing contact materials. Letters and emails will be personalized with the respondent’s name. A personalized letter will maximize the chances that the request makes it to a school or district respondent, compared with a letter addressed to “Dear Superintendent” or “Dear Principal.” Email messages with a salutation that includes a respondent’s name may increase the chances that the message is opened and read.
Telephone and personalized email follow up for nonresponse. About three weeks after the start of data collection, interviewers will begin telephone and individualized email follow up with respondents in districts and schools. Interviewers are trained in effective communication strategies with district and school respondents. The study management system will also allow interviewers to send personalized email messages to respondents, answering their questions and providing them with their survey login information.
Use of incentives for survey completion. The study is proposing the use of incentives for principals. If approved by OMB, the proposed incentive is $20 to be paid upon survey completion. The 2014 survey for the study used the same strategy being proposed for the 2022 surveys.
B.4. Test of Procedures
The study team pretested each survey with nine or fewer respondents to ensure that questions are clear and that the average survey completion time is within expectations.
B.5. Individuals Consulted on Statistical Aspects of Design
The individuals consulted on the statistical aspects of the study sample design include:
Patty Troppe, Westat, Vice President and Project Director
Lou Rizzo, Westat, Senior Statistician
Keith Rust, Westat, Senior Vice President, Statistics and Evaluation Sciences Practice
Brian Gill, Mathematica, Principal Investigator
1The 2019-20 CSI universe file was prepared by Westat for IES. For most states, the CSI school data come from EDFacts. However, for four states, the data come from the state’s website. For one additional state, within sampled districts, we supplemented the list of CSI schools with information from the state’s website.
2See footnote 1 for source information.
3District urbanicity, a key analysis variable, is incorporated into the sample design through a later implicit stratification step.
4Note that the percentiles are weighted percentiles, weighted by enrollment, so that for example the high poverty district represents 25% of enrollment, not 25% of districts, with the highest poverty levels.
5Note that in some cases percentage of families with children in poverty was missing. When percent children eligible for free or reduced-price lunch was available, we imputed children in poverty based on a regression model (based on districts that had both variables nonmissing).
6We will limit the district sampling frame to LEAs that have an LEA_TYPE of 1, 2 or 7. In the case of Vermont (VT) and New York City (NYC), for districts associated with a supervisory union (SU) we will include the SU rather than the individual districts. This approach to VT and NYC is consistent with past samples and studies.
7We call this a ‘minimax’ approach in which we use a stratified random sample of districts (equal probabilities within strata), with higher sampling rates proportional to the square root of mean district enrollment (within the stratum). This approach balances the need for precision for ‘unit-based’ national district estimates (where each district counts as one in the population), and the need for providing the school sample size in the next stages of the design. An allocation simply proportional to the number of districts would strongly favor the medium-poverty stratum, which has more than 50 percent of the districts. The study team used a similar minimax approach for the 2018 and 2014 Title I/II-A district sample.
8These cutoffs reflect the empirical distribution of CSI schools within districts.
9For more information, see: Evaluation Studies of the National Center for Education Evaluation and Regional Assistance - Study of District and School Uses of Federal Education Funds
10For more information, see: Evaluation Studies of the National Center for Education Evaluation and Regional Assistance - Implementation of Key Federal Education Policies in the Wake of the Coronavirus Pandemic. The Study of the Uses of Federal Education Funds used a large subsample for their own 2021 data collection, except for 10 certainties included for that study alone.
11For more information, see: Evaluation Studies of the National Center for Education Evaluation and Regional Assistance - National Implementation Study of Student Support and Academic Enrichment Grants (Title IV, Part A)
12For more information, see: Evaluation Studies of the National Center for Education Evaluation and Regional Assistance - Study of Educational Policies, Supports and Practices for English Learners: Implementation of Title III and Social and Emotional Learning
13 Compared to the 2021 Coronavirus Pandemic district sample, the Uses of Funds district sample included 10 extra certainty districts. When maximizing the overlap of the Title I/II district sample and the 2021 Coronavirus Pandemic district sample, these 10 districts will be included. All of the probabilities of selection will be defined in such a way that when taking the expectation over all possible samples from district studies, the unconditional probabilities for the Title I/II-A sample will be as specified in the proposed sampling design above. See for example Ernst, L. R., and Paben, S. P. (2002). “Maximizing and Minimizing Overlap When Selecting Any Number of Units per Stratum Simultaneously for Two Designs with Different Stratifications,” Journal of Official Statistics 18 (2), 185-202 for a discussion of this theory and further references.
14We also carry through the poverty-stratum differential sampling rates fully from districts to schools: both levels are oversampled at the same constant rate.
15The
usual formula for a design effect from clustering is
 ,
where
,
where
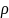 is the within-cluster correlation coefficient, and
is the within-cluster correlation coefficient, and
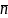 is the mean cluster size. This is generally the formula used, but it
is actually an underestimate if the cluster sizes differ
significantly from the mean cluster size. This will not be true for
non-CSI schools, but the cluster size for CSI schools (the number of
CSI schools sampled within sampled districts) will have to vary
quite a bit. For CSI schools then we will use the more accurate
approximation
is the mean cluster size. This is generally the formula used, but it
is actually an underestimate if the cluster sizes differ
significantly from the mean cluster size. This will not be true for
non-CSI schools, but the cluster size for CSI schools (the number of
CSI schools sampled within sampled districts) will have to vary
quite a bit. For CSI schools then we will use the more accurate
approximation
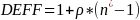 where
where
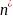 is
multiplied to 1 plus the squared coefficient of variation of the
cluster sizes. This revised formula can be found in Chen, S., and
Rust, K. (2017), “An Extension of Kish’s Formula for
Design Effects to Two- and Three-Stage Designs with Stratification”,
Journal of Survey Statistics and Methodology 5, 111-130.
is
multiplied to 1 plus the squared coefficient of variation of the
cluster sizes. This revised formula can be found in Chen, S., and
Rust, K. (2017), “An Extension of Kish’s Formula for
Design Effects to Two- and Three-Stage Designs with Stratification”,
Journal of Survey Statistics and Methodology 5, 111-130.
16The
adjusted cluster size
is
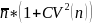 =
2*(1+0.832) = 3.36.
=
2*(1+0.832) = 3.36.
17Unit-based estimates meaning each district counts as 1 in the population. This is opposed to a student enrollment-based estimate.
18The design also provides good power for other district subgroup comparisons of interest. For example, the MDD for comparing small districts (2,500 students or less) and medium districts (2,500 to 25,000 students) is 10 percent. The MDDs for comparing large districts (25,000 students or more) to both other size domains range from 15.4 percent to 15.7 percent. The MDDs for comparing urbanicity groupings (urban v suburban, urban vs other, urban vs rural/town) range from 12.4 percent to 15.4 percent.
19The design also provides good power for other school subgroup comparisons of interest. For example, the MDD for comparing Title I and non-Title I schools is 12.4 percent. The MDDs for comparing grade levels (elementary vs middle, elementary vs high, middle vs high) range from 12.1 percent to 15.3 percent.
20The intra-district correlation will vary across questionnaire items: items representing policy set at the district level may show a high correlation across schools in a district, whereas other school-specific items will show a lower correlation. We assume 25 percent as a reasonably conservative value.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| File Modified | 0000-00-00 |
| File Created | 2022-01-05 |
© 2026 OMB.report | Privacy Policy