TRLECE Full OMB-Supporting Statement B
TRLECE Full OMB-Supporting Statement B.docx
The Role of Licensing in Early Care and Education (TRLECE)
OMB: 0970-0602
Alternative Supporting Statement for Information Collections Designed for
Research, Public Health Surveillance, and Program Evaluation Purposes
The Role of Licensing in Early Care and Education (TRLECE)
OMB Information Collection Request
0970 – New Collection
Supporting Statement
Part B
OCTOBER 2022
Submitted By:
Office of Planning, Research, and Evaluation
Administration for Children and Families
U.S. Department of Health and Human Services
4th Floor, Mary E. Switzer Building
330 C Street, SW
Washington, D.C. 20201
Project Officers:
Ivelisse Martinez Beck, Ph.D.
Part B
B1. Objectives
Study Objectives
The Role of Licensing in Early Care and Education (TRLECE) information collection includes three surveys. The objectives of each are outlined here.
The objective of the child care licensing administrator survey is to collect information about licensing systems from administrators’ perspectives. Specifically, we plan to collect data to help characterize:
Licensing administrator demographics
Licensing agency structure and staff supports
Licensing administrators’ ideas about the factors that influence decision-making
Licensing administrators’ perceptions of strengths and challenges of the licensing system
Licensing administrators’ ideas to improve the licensing system
The objective of the front-line child care licensing staff survey is to collect information about front-line licensing staff members from their own perspectives. Specifically, we plan to collect data to help characterize:
Front-line staff members’ roles, day to day responsibilities, demographic characteristics, career paths, professional development experiences, relationships with colleagues and providers, and burnout/work satisfaction
The role of front-line licensing staff in supporting quality/quality improvement
Front-line staff’s perceptions of strengths and challenges of the licensing system
The objective of the child care provider survey is to fill a major gap in our knowledge about child care licensing by asking providers about their experiences with and perceptions of the licensing system. Specifically, we plan to collect data to help us characterize:
Child care providers’ perceptions of the burden, value, and fairness of the licensing system
Child care providers’ perceived strengths of and challenges with the licensing system
Generalizability of Results
The child care licensing administrator survey and front-line child care licensing staff survey are intended to present internally valid descriptions of the characteristics and perceptions of child care licensing administrators in each state/territory and front-line child care licensing staff in each state, not to promote statistical generalization to other populations. The child care provider survey is intended to produce findings that are generalizable to the population of licensed child care providers in the U.S.
Appropriateness of Study Design and Methods for Planned Uses
A survey approach will allow the TRLECE team to collect information from all states and territories for the licensing administrator survey and all states for the front-line staff survey, as well from a large, nationally representative sample of licensed child care providers. The majority of questions in each survey will be closed-ended; with a few open-ended questions in each survey. Closed-ended survey questions are ideal for collecting information on topics where the range of likely responses is known. The open-ended questions allow for collection of information about individuals’ unique experiences and perceptions. This two-pronged approach will minimize burden while also providing sufficient detail to answer all proposed research questions and goals.
The information gathered will be purely descriptive. We will not collect evaluation information and the information collected will not be used to assess state systems or evaluate impact. Key limitations will be included in written products associated with this information collection. As noted in Supporting Statement A, this information is not intended to be used as the principal basis for public policy decisions and is not expected to meet the threshold of influential or highly influential scientific information.
B2. Methods and Design
Target Population
The target population for this information request includes all child care licensing administrators in all U.S. states, territories, and the District of Columbia (DC); all front-line child care licensing staff in all U.S. states and DC; and a nationally representative sample of directors/owners/managers of licensed child care programs that serve children between birth and age 13 in all U.S. states and DC. We are not including U.S. territories in the child care provider surveys because lists of providers in U.S. territories are typically not publicly available. We are not including U.S. territories in the survey of front-line child care staff because we aim to look at similarities and differences in the perceptions of licensing of child care providers and front-line child care staff, so we want the respondents to be drawn from the same underlying population (i.e., all states, but not territories). The unit of analysis for the licensing administrator survey will be the state/territory licensing administrator (N = 56). The unit of analysis for the front-line child care licensing survey will be the front-line staff member (N~=3,000). The population of front-line staff is relatively small, so including and following up with all of them is feasible and will likely result in an adequate sample size for our analyses. The unit of analysis for the child care provider survey will be the center or family child care provider. Based on data reported by state CCDF lead agency representatives in the FY2021 Quality Progress Report,1 we estimate that the total population of licensed child care providers is approximately 220,710.
Sampling
We plan to conduct a census data collection for the licensing administrator and front-line staff surveys, inviting all child care licensing administrators in all U.S. states, territories, and DC to participate in the licensing administrator survey and all front-line child care licensing staff in all U.S. states and DC to participate in the front-line staff survey. We know that the experiences of licensing administrators in each state and territory are unique; states and territories vary in how their child care licensing system is organized and operated. For that reason, it is important to collect data from as many states and territories as possible to fully explore this variation. For the front-line staff survey, we are proposing a census because this is a population that has not been studied in the past, so we know very little about it. This lack of prior information makes it impossible to create a statistically representative sample at the national level. We anticipate large variation in the number of front-line staff across states, with some states having only a few, so including the entire population will ensure that each state is well represented.
The goal of the child care provider sampling plan is to develop a sample of providers that can be weighted to create national estimates of 1) all licensed providers, 2) licensed center providers, and 3) licensed family child care providers. Additionally, we aim to have enough licensed providers in each state and DC to allow for analysis of the association between state-level policies and providers’ perceptions of the licensing system. To meet these sampling goals, we will use two simple random samples, one of centers and a second of family child care providers. We will oversample in small states to ensure a minimum of 5 respondents in each state, plus DC, in each sample (centers and family child care providers). We conducted a power analysis using a sample policy (whether licensing is overseen at the state or county level) as a predictor of a hypothetical set of survey items measured on a five-point scale with a mean of 3.75 and a standard deviation of .75. Using this policy, an expected medium effect size (Cohen’s d = 0.5), an alpha level of .05 and a moderate (.1) ICC, we found that a sample of 1,000 would be sufficient to give us .8 power.2 This policy was chosen as a potentially relevant one that was present in a smaller number of states (5 states). The oversample (i.e., minimum response of 5 centers and 5 family child care homes in each state and DC) will increase our chances that if a given policy was present more often in smaller states, we will still have enough data for these states to draw a robust conclusion.
The first step in sampling for the child care provider survey will be to create a sampling frame that includes the entire target population of licensed child care providers in all 50 states and DC. The TRLECE team will develop this list using primarily information published on state licensing websites. States maintain websites that list licensed child care providers and their licensing inspection findings. In many states, there is a function on the website that allows the underlying data to be exported; in states with that feature, we will use it. In states that do not have a download feature but do allow public scraping of their websites, we will use Python’s extensive web scraping tools to collect a list of providers. In states where scraping is not allowed, we will generate a list of providers by manually copying provider information into a database or working with our contacts at the state level to obtain the list. These lists from all 51 states and DC will be combined to form an authoritative and complete list of licensed providers nationwide. Once we have a list of providers for each state and DC, we will identify and remove duplicate cases using a statistical software program.
Our goal is to have a list that includes program name, program address, provider name, and provider email address. Some state websites, however, may lack some of the contact information. For providers who are randomly selected into our sample, we will use Google Places API, a service that allows for the lookup of specific details associated with a particular location, in this case a child care program, to gather missing contact information when they are not on the state list. In cases where that information is unavailable in Google Places API, we will manually look up contact details on the internet. For selected programs for which we are unable to find a provider’s email address, we will modify our outreach efforts to contact them via mail and telephone only (see Part B4).
B3. Design of Data Collection Instruments
Development of Data Collection Instruments
The state child care licensing administrator survey was developed through a review of existing surveys for other child care related professionals (e.g., the 2019 National Survey of Early Care & Education; the 2017 and 2020 Child Care Licensing Study survey; Infant and Early Childhood Mental Health Consultation evaluation surveys), consultation with licensing experts (Nina Johnson – ICF), and interests expressed by OPRE and OCC. We gathered feedback on the survey from technical expert panel (TEP) members and the state licensing panel. We also piloted this survey with three former licensing administrators.
The front-line child care licensing staff survey was developed through a review of existing surveys for other child care related professionals (e.g., the 2019 National Survey of Early Care & Education; the 2020 Child Care Licensing Study survey; Infant and Early Childhood Mental Health Consultation evaluation surveys) and consultation with licensing experts (Nina Johnson – ICF). We gathered feedback on the survey from TEP members and the state licensing panel. We also piloted this survey with two former front-line staff members.
The child care provider survey was developed in consultation with licensing experts (Nina Johnson and Nancy VonBargen – ICF), and informed by existing surveys of child care providers (e.g., the 2019 National Survey of Early Care & Education, Study of Coaching Practices in Early Care and Education Settings: Teacher and Family Child Care Provider Survey OMB #0970-0391), as well as existing studies examining provider perceptions of child care and early education (CCEE) licensing (Bromer et al., 2021; Rohacek et al., 2010; Shadimah, 2018). We gathered feedback on the survey from TEP members and the state licensing panel. We then piloted the tool with five current or former child care providers (three center directors and two family child care providers).
As we piloted each survey, we also requested that respondents provide feedback to us on characteristics of the survey itself (e.g., did the items make sense, did the response options comprehensively capture their experiences, do they suggest any changes). This feedback helped us refine survey items and decrease the cognitive burden on participants. We also tracked how long it took respondents to complete the survey to ensure they were not taking more time than estimated. As a final step, we added/edited some questions to incorporate feedback received during the 30-day public comment period (see Appendix H).
B4. Collection of Data and Quality Control
Who will be collecting the data?
The Contractor (Child Trends) will administer the surveys directly to each child care licensing administrator, front-line staff, or child care provider primarily via the web, with telephone as an option. In states that are unable to provide lists of front-line staff, we will work with licensing administrators to directly distribute anonymous survey links to their front-line licensing staff on our behalf.
What is the recruitment protocol?
Child care licensing administrator recruitment protocol. We will contact all licensing administrators in every U.S. state and territory via email and telephone (see Appendix A for email text and phone scripts).
Front-line child care licensing staff recruitment protocol. We will request that licensing administrators complete a brief survey about the best times to contact front-line staff and provide their contact information (approved through a generic OMB package, OMB #0970-0356; The Role of Licensing in Early Care and Education). Once we receive contact information for front-line staff, we will contact them via email and telephone (see Appendix B for email text and telephone scripts). If we do not hear back from a state at all, we will search for and use any publicly available contact information for front-line staff.
Child care provider recruitment protocol. For each provider in our sample, we will attempt to gather mailing address, email address, and telephone number in advance. However, we may not have access to all three pieces of information for all selected providers. For that reason, we plan to use a combination of outreach methods, tailored to the provider, depending on the information we have. If we have mailing address, we will start with a letter, and follow up by email and phone, if that information is available. If we do not have mailing address, we will start with email and follow up by phone, if that information is available (see Appendix C for mail and email text, as well as telephone scripts).
Despite our strong outreach efforts, we are aware that child care providers are a difficult group to engage in research. Therefore, we will start by selecting and recruiting 3,125 center directors/owners and 3,125 family child care providers, with a minimum of 15 center directors/owners and 15 family child care providers in each state (see Part B2 for the child care provider sampling plan). The initial outreach numbers are based on the assumptions that 20 percent of those selected will be ineligible (e.g., closed, no longer licensed) and 60 percent of those who are eligible will not respond (see Part B5 for details about response rates). After five weeks of recruitment, if we have not yet reached our goals (1,000 center responses, 1,000 family child care responses, and at least five responses in each group in each state), we will select additional providers for recruitment. Additional centers and family child care providers will be selected at random, with the exact number of each type in each state depending on the rates of ineligibility and response until that point. Recruitment will continue until our recruitment targets by group and by state are met or for five months, whichever is shorter. Additionally, our outreach materials will give providers a way to inform us if their program is no longer operating or if they do not wish to participate.
What is the mode of data collection?
Data collection will be conducted via online surveys hosted through REDCap, our secure online data collection platform. In cases where the survey is administered over the phone, responses will be entered into REDCap by the data collector.
What data evaluation activities are planned as part of monitoring for quality and consistency in this collection, such as re-interviews?
While respondents are taking the survey, REDCap’s built-in validation functions will ensure responses are within expected ranges. If the response does not pass validation, the participant will be prompted to correct the response. If participants start the survey but do not complete it, reminder emails will be sent as part of the outreach efforts (see Appendices A-C). Throughout the data collection, we will monitor the survey responses weekly and conduct weekly quality assurance checks.
What is the proposed approach for selecting, recruiting, and training data collectors?
Project team members from the Contractor will be trained to conduct phone calls to survey respondents. The task lead and activity lead for each survey will train and supervise staff to call individuals who have not yet responded to remind them to take the survey, using a standardized script. If the individual answers, the data collector will offer to conduct the survey over the phone.
B5. Response Rates and Potential Nonresponse Bias
Response Rates
For all three surveys, we will encourage response by providing a compelling rationale for how completing the survey will help the field, sending reminders in multiple modalities, and offering a $25 token of appreciation (see Supporting Statement Part A9 for additional information). Respondents will have the flexibility to complete their surveys online at their own pace or over the phone.
The licensing administrator survey is a one-time census survey in which all licensing administrators will be asked to participate. Response rates will be calculated as a percent of responses received out of the total number of surveys sent out. Recently, the TRLECE team conducted interviews with licensing administrators with a response rate of 86% (48 out of 56 licensing administrators).3 We expect a similar response rate.
The front-line child care licensing staff survey is a one-time census survey in which all front-line staff will be asked to participate. There have been no other studies of front-line licensing staff from which we can directly base our response rate estimate; however, a recent national study of the home visitation workforce reported a 55 percent response rate (OPRE Report #2020-974). Like front-line child care licensing staff, home visitors are professionals working directly with a caseload of individuals within the CCEE system. We use this estimate, in conjunction with corroborating perspectives from CCEE licensing experts on our team, to estimate that we will have approximately a 55 percent response rate from front-line child care licensing staff.
The child care provider survey will be sent to a sample of child care providers, with the goal of receiving responses from 2,000 licensed providers nationwide (1000 center directors/owners and 1000 family child care providers), with a minimum of at least ten responses from each state (5 center directors/owners and 5 family child care providers; see sections B2 and B4). We estimate that roughly 20 percent of the programs on our nationwide list will be ineligible (e.g., closed, no longer licensed)5 and we expect to get approximately a 40 percent response rate from eligible licensed providers. This estimate is based on response rates from the mail and telephone phases of the 2012 National Study of Early Care and Education (NSECE) (see Exhibit 4 of OMB #0970-0391).
For all three surveys, valid surveys will be those where at least one substantive question (i.e., not including a screener question) was answered. Response rate will be calculated using the American Association of Public Opinion Researchers’ Standard Response Rate 4 (American Association for Public Opinion, 2015; one of the most widely accepted standards in survey research) which uses the formula:
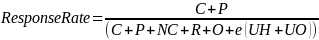
Where each of the terms is defined as:
C |
Completed surveys by eligible respondents |
P |
Partially completed surveys by eligible respondents |
NC |
Non contacts: Respondent unable to be contacted (e.g., email bounce back) |
R |
Refusals |
O |
Other situations in which a respondent was unable to respond |
e |
Anticipated eligibility rate |
UH |
Unclear if address is correct |
UO |
Other non-response of unknown eligibility |
For the front-line child care licensing staff and child care provider surveys, we will calculate unit response rates, both nationally and within each state. The national response rate, as well as the state-level average and standard deviation, will be included in all reports.
For all three surveys, respondents will be permitted to skip any questions they do not want to answer. Item-level response rates will be calculated for each item. To calculate item level response rates, we will divide the number of valid surveys by the number of valid answers to each item. Item level response rates will be reported in technical documentation, when necessary to explain analysis decisions or contextualize results.
NonResponse
Child Care Licensing Administrators
Participant NonResponse. For the child care licensing administrator survey participants will not be randomly sampled and findings are not intended to generalize beyond this specific population. We will qualitatively compare respondent and non-respondent states/territories using information from the 2017 CCLS (Child Care Licensing Study; see Supporting Statement Part A4; e.g., number of licensed child care facilities, agency that houses child care licensing) and describe ways in which nonresponse may have biased the results. Additionally, respondent demographics will be documented and reported in written materials associated with the data collection.
Item NonResponse. For questions about the licensing systems that we plan to report linked to state/territory name (i.e., Part 1 of Instrument 1), missing information will be noted in the reports and online information. It will not be imputed because the imputed values will not be accurate enough to report at the individual state/territory level. For descriptive information regarding perceptions and ideas that we plan to aggregate for reporting (i.e., Part 2 of Instrument 1), item non-response will be handled using a standard multiple imputation approach (e.g., Sinharay et al., 2001). Item non-response rates will be reported and any outlier items (i.e., those with significantly higher item non-response rates than other items) will be noted and discussed.
Front-line Child Care Licensing Staff
Participant NonResponse. For the front-line licensing staff survey, participants will not be randomly sampled, and findings are not intended to generalize beyond this specific population. Little information is known about this population, but respondents and non-respondents may differ in important ways so we will identify and correct nonresponse bias to the extent possible. To do this, we will apply two of the most common approaches to identifying and correcting non-response bias: 1) creating post-stratification weights using the known characteristics of the population, and 2) comparing initial responders to responders acquired through repeated follow up attempts (Groves & Peytcheva, 2008).
The only variable on which we can create post-stratification weights is state because this is the only piece of information we will know about the population of front-line staff; however, state is an important variable because child care licensing rules and policies are largely determined by the state. We will therefore create post-stratification weights to match the distribution of respondents to the distribution of front-line staff across states. Respondents in states with low response rates will have higher weights whereas respondents in states with higher response rates will have lower weights. For each state, the weight will be calculated as:

We will conduct our key analyses using both weighted and unweighted data and conduct sensitivity analysis to determine if the weighted and unweighted results differ; if results do not differ significantly, unweighted results will be presented for ease of interpretation, otherwise weighted results (both descriptive and analytic) will be presented. While this approach allows us to correct for non-response bias that comes from front-line staff in certain states responding at a lower rate than others, this approach will not allow us to account for other differences between responders and non-responders (e.g., gender, race, income) because we will not have additional information about non-responders.
Therefore, we will supplement our post-stratification with a second common tactic (Groves & Peytcheva, 2008) used for addressing non-response bias, which is to compare responses from early responders (i.e., those who respond within two weeks of our first contact) to responses from late responders (i.e., those who responded more than two weeks after our first contact, meaning they received several rounds of follow-ups). This works under the assumption that late responders are more similar to non-responders than are early responders. If the responses of early and late responders differ, we will produce response propensity weights which will be used to weight data based on any differences between early and late responders. As with the state weights, we will conduct analyses with both weighted and unweighted data and conduct sensitivity analyses to identify any differences. For simplicity, we will report the unweighted results unless the weighted and unweighted are significantly different. If both types of nonresponse weighting (state-level and early/late responder) are significantly different, the two will be applied in combination.
Additionally, respondent demographics will be documented and reported in written materials associated with the data collection.
Item NonResponse. Item nonresponse will be handled using a standard multiple imputation approach (e.g., Sinharay et al., 2001). Item nonresponse rates will be reported and any outlier items (i.e., those with significantly higher item nonresponse rates than other items) will be noted and discussed.
State NonResponse. Based on our past relationships with licensing administrators, we anticipate that we will be able to invite all front-line staff to complete this survey, either by sending the links directly or by having the administrators send the link on our behalf. However, there is a chance one or more states will not respond to our request and we will be unable to find publicly available lists, meaning the entire state will be excluded from the survey. We aim to avoid this scenario. However, if it occurs, we will describe the state(s) that are missing in terms of size and known licensing characteristics (without naming them) and carefully report our findings to make clear that they only apply to the states that participated.
Survey of Child Care Providers
Participant NonResponse. As with the survey of front-line staff, for the survey of child care providers, respondents and non-respondents may differ in important ways so we will identify and correct nonresponse bias to the extent possible using the same two strategies described above : 1) creating post-stratification weights using state and 2) comparing initial responders to responders acquired through repeated follow-up attempts (Groves & Peytcheva, 2008). As with the survey of front-line staff, we will conduct the analysis both with and without the weights and only report the weighted results if they change the findings.
Additionally, respondent demographics will be documented and reported in written materials associated with the data collection.
Item NonResponse. As with the Front-line Child Care Licensing Staff survey, item nonresponse will be handled using a standard multiple imputation approach (e.g., Sinharay et al., 2001). Item nonresponse rates will be reported and any outlier items (i.e., those with significantly higher item nonresponse rates than other items) will be noted and discussed.
B6. Production of Estimates and Projections
Child Care Licensing Administrator Survey. Because we plan to include the entire population of licensing administrators, we will not need to create design weights for this survey. Further, weights to account for nonresponse are not appropriate because there is only one respondent per state/territory and each state/territory is so different that increasing the weight for any single state/territory to account for nonresponse by another state/territory would not be meaningful. Instead, our estimates will be based purely on our respondents, and we will document and report nonresponse and how it might affect our estimates.
Front-Line Child Care Licensing Staff Survey. Because we plan to include the entire population, we will not need to create design weights for this survey. We will create response propensity weights to account for any differences in response rates by state and to adjust for nonresponse using early/later response status, as described in the non-response section (B5). We will also conduct sensitivity analysis to determine if the weighting changes the reported results and only apply weights that affect the results.
Child Care Provider Survey. Estimates from the child care provider survey are intended to be generalizable to licensed child care providers, for official external release by the agency. We will create three sets of design weights: one for national estimates of all licensed providers, one for centers, and one for family child care homes. The design weights will account for the differential selection probabilities created by the stratification by program type and oversampling of small states. Each weight will be the inverse of the odds of each provider’s selection probability. Once design weights have been applied, we will then create response propensity weights to adjust for nonresponse bias as described in section B5.
We will combine the design weights and response propensity weights by first calculating and applying design weights, and then calculating and applying response propensity weights (e.g., Dutwin & Buskrik, 2017; see Mercer et al., 2018 for a plain-language overview).
We plan to archive all data gathered from these three surveys with the Child and Family Data Archive , so they can be analyzed by other researchers. The documentation will include descriptions of how the weights were developed, code to create weights, sensitivity tests that we conducted, as well as detailed instructions for appropriately applying the weights.
B7. Data Handling and Analysis
Data Handling
For all three surveys, the TRLECE team will build validation checks into the REDCap survey platform to ensure responses are within expect ranges. Skip logic will allow respondents to only respond to questions that are relevant to them. The survey team will also conduct ongoing reviews of the data, including frequencies and cross tabulations, to ensure each survey is running as expected. The data will be stored on REDCap’s secure server. Only research team members who have completed human subjects research and data security training will have access to data collected through the REDCap survey.
Data Disposition Plan
Once data collection is complete, data will be downloaded to Child Trend’s secure server and personal identifiers will be permanently removed from data that will be reported in aggregate.6 Questions related to structural or procedural features of state/territory licensing systems will be linked to their state name in public reports.
Data Analysis
Child Care Licensing Administrator Survey. We will use both quantitative and qualitative methods to analyze the licensing administrator survey data. For all closed-ended survey questions, we will calculate descriptive statistics (minimum/maximum values, frequencies, means, and standard deviations) for the overall sample. Examples of specific descriptive analyses we plan to include:
What is the educational background of licensing administrators?
In what percentage of states are front-line licensing staff involved in making enforcement decisions?
Open-ended questions from the licensing administrator survey will be coded using a qualitative content analysis approach in Dedoose coding software. A team of between two and four coders most knowledgeable about the topic will independently review a random subsample of 5 responses from each open-ended question and make notes on themes and patterns. Coders will meet along with the survey activity leads and/or the task leads to discuss the possible themes and develop an initial coding structure for each open-ended question. The coders will then independently apply this initial coding structure to a second random subsample of 5 open-ended responses to ensure that the survey’s coding structure is distinctive and coherent. As they are coding these responses, new codes and themes will emerge. Researchers will meet, along with the task and/or activity leads, to review the emerging themes and to come to consensus on how codes are defined and applied. During this process, the researchers will create and refine a codebook which describes the codes and their application. If significant changes are made to the coding structure based on the reconciliation of the coding of the first 5 open-ended responses for each question, the team will randomly select up to 5 more responses to review, code, and discuss.
Once the coding structure has been finalized, coders will double code all open-ended responses. The coders will meet at regular intervals during coding to confirm agreement and to come to consensus in case of disagreement. The task or activity leads will serve as a “tie breaker” when agreement cannot be reached. Instances of differing opinion, as well as the resolution, will be documented. The team will also discuss new codes if they emerge and will review previously coded responses to apply new codes as needed.
Front-Line Child Care Licensing Staff Survey. We will use both quantitative and qualitative methods to analyze the front-line child care licensing staff survey data. All closed-ended survey questions will follow the same descriptive data analysis strategy outlined for the licensing administrator survey above. Examples of the types of specific descriptive analysis we plan to include:
What are typical wages for front-line staff?
What topics are covered in professional development for front-line staff?
Coding the responses to the open-ended questions from the front-line child care licensing staff survey will follow the same strategy outlined above for the licensing administrator survey; the only difference will be the number of random responses reviewed. Because the number of respondents will be much larger, instead of a random subsample of 5 responses, a random subsample of 50 responses will be reviewed throughout the data analysis and coding process.
To look at associations between variables from the front-line staff survey data, we will first examine intraclass correlation coefficients (ICCs) for outcomes of interest to examine if there is nesting at the state-level. If ICCs indicate significant levels of nesting, we will use multi-level modeling to account for the nesting of front-line staff members within states. If ICCs do not indicate significant nesting, we will examine associations without use of multi-level modeling. Examples of specific associations among variables we will examine include:
What is the association between front-line staff members’ training and reported self-efficacy?
What is the association between caseload and job stress?
Child Care Provider Survey. We plan for two primary types of analysis: 1) nationally representative descriptive analyses of all licensed providers, of center-based providers, and of family child care homes, and 2) multi-level models estimating associations between variables.
For the nationally representative descriptions, we will use the nationally representative weighted data sets described above. The types of questions we will answer using these nationally representative descriptive analyses include:
On average, do providers in the U.S. think licensing regulations are relevant to their program (on a Likert scale)? Do their perceptions depend on if they are from a center-based program or a family child care home?
What do providers perceive to be the benefits of participating in the licensing system?
These analyses will be descriptive and include means, standard deviations, and frequencies. Open-ended questions will be coded qualitatively.
In order to look at associations between variables, we will use multi-level modeling to account for the nesting of providers within states. These analyses will primarily use state-level CCEE licensing policies as the independent variables and provider responses as the dependent variables. State policy information will come from the CCLS, interviews TRLECE conducted in 2021 of state licensing administrators (OMB #0970-0356; Understanding Child Care Licensing Challenges, Needs, and Use of Data), document reviews, and state/territory profiles we are creating as part of the larger TRLECE contract. Examples of types of questions we can explore using multi-level modeling include:
Do providers in states that manage licensing at the county-level, as compared with those that manage licensing at the state-level, have more/less positive views of the licensing process?
Do family child care providers in states with a low threshold for licensing family child care (e.g., require family child care provider serving fewer than three children to be licensed), as compared with those in states with a higher threshold (e.g., require family child care provider serving three or more children to be licensed) for licensing family child care, have more/less positive views of the licensing system?
Do providers in states where licensing is part of QRIS (Quality Rating and Improvement System; e.g., being licensed automatically enrolls a program in QRIS and awards one star) feel that licensing is more likely to support quality improvement in their program than those in states were QRIS and licensing operate separately?
Data Use
The project team will use the licensing administrator survey data in two ways: 1) to create a public report and 2) to inform public state/territory licensing profiles. The public report may include state-/territory-specific information from Part 1 of the survey, but all data from Part 2 will be presented in aggregate only. This report will provide insight into licensing administrators’ child care experiences and perceptions of the licensing system, providing important information about the CCEE licensing system to policymakers, state/territory administrators, and those working in licensing systems themselves. The publicly available state/territory licensing profiles will provide information about structural and procedural features of state/territory licensing systems to inform others about state/territory licensing systems. These data will be linked to state/territory names.
Results from the front-line staff survey data will be used to create a public report. This report will provide insight into front-line staff’s demographic characteristics, roles, responsibilities, and perceptions of the licensing system. This will provide important information about the CCEE licensing system to policymakers, state administrators, researchers, and staff working in licensing agencies.
Results from the child care provider survey data will be used to create a public report. This report will provide insight into providers’ perceptions and experiences with their CCEE licensing system. This will provide important information about the CCEE licensing system to policymakers, state administrators, child care providers, staff working in licensing agencies, and researchers.
The TRLECE team plans to archive the data from all three surveys through the Child and Family Data Archive. These data will be made available for secondary data analysis at the end of this information collection. Before archiving the data, we will ensure that any potentially personal identifying information is stripped from the public use data, including ensuring that anything that is potentially identifying in open-ended responses is removed from the public-use data set. Data sets that contain potentially identifying information (e.g., state identifiers) will be available only through restricted use. We will prepare a data user manual that describes the design, data collection procedures and instruments, data preparation procedures, and data file structure used by the TRLECE team to support the use, analysis, and interpretation of the data collected. The manual will also describe limitations.
We do not intend for policy decisions to be made based on these data.
B8. Contact Persons
Kelly Maxwell
TRLECE PI
Senior Research Scholar for Early Childhood Department
Child Trends
1516 E Franklin St, Suite 205 | Chapel Hill, NC 27514
kmaxwell@childtrends.org
(919) 869-3251
Diane Early
Research Scholar for Early Childhood Department
Child Trends
7315 Wisconsin Ave, Suite 1200W | Bethesda, MD 20814
dearly@childtrends.org
(406) 570-2037
Ivelisse Martinez Beck
Child Care Research Team Lead, Project Officer
Office of Planning, Research, and Evaluation
Administration for Children and Families
US Department of Health and Human Services
330 C Street, SW | Washington, DC 20024
imartinezbeck@acf.hhs.gov
(202) 690-7885
Attachments
Instrument 1: Child care licensing administrator survey
Instrument 2: Front-line child care licensing staff survey
Instrument 3: Child care provider survey
Appendix A: Recruitment of child care licensing administrators
Appendix B: Recruitment of front-line child care licensing staff
Appendix C: Recruitment of child care providers
Appendix D: Letter of Support from OCC
Appendix E: Project flyer for licensing administrators
Appendix F: Federal Register Comment received after 60-day period for public comment
Appendix G: Federal Register Comments received during 30-day period for public comment
Appendix H: Response to comments received during 30-day period for public comment
1 The CCDF Quality Progress Report (ACF-218) is approved under OMB #: 0970-0517.
2 Power calculated using GLIMMPSE software. https://glimmpse.samplesizeshop.org/
3 Understanding Child Care Licensing Challenges, Needs, and Use of Data was approved under OMB #0970-0356.
4 https://www.acf.hhs.gov/opre/report/home-visiting-careers-how-workplace-supports-relate-home-visitor-recruitment-and (Information collection that informed this report was approved under OMB #0970-0512).
5 We are basing this estimate of ineligibility on our professional expertise. As far as we know, no other study has created a sampling from state websites of licensed providers, so we do not have another source for this information. However, even if it is inaccurate, we will likely still obtain our desired sample size by sending out a second batch of requests. See Part B4.
6 Not all information will be aggregated or deidentified prior to reporting. Some items from the Administrator Survey will be reported in public profiles that include state names. This information is clearly described in Administrator Survey outreach materials (Appendix A) and the survey itself (Instrument 1).
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | Alexandra Verhoye |
| File Modified | 0000-00-00 |
| File Created | 2023-08-01 |
© 2026 OMB.report | Privacy Policy